Hello everyone! Welcome back to the series where we push the limits of local AI on a not-so-average homelab: the NVIDIA DGX Spark.
In my previous post, we battled Bangkok’s heat and learned a valuable lesson about system prompts and Prefix Caching while testing Claude Code against OpenCode. Today, I’m excited to share that the system has evolved. I’ve completely overhauled the architecture to transform it from a standalone server into a true, enterprise-grade “Model-as-a-Service” infrastructure.
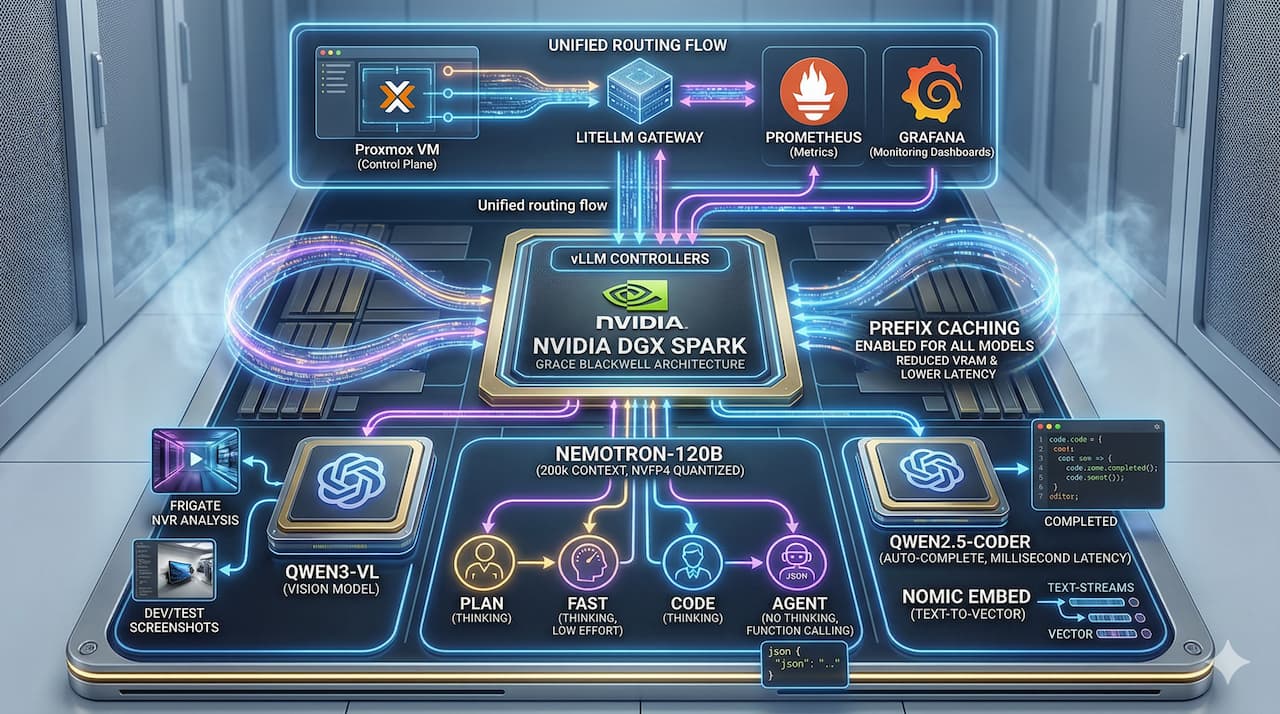
Here is the high-level architecture of what we are building today:
🏗️ Architecture Overview
Here is how I squeezed every drop of performance out of this Blackwell beast to make this architecture a reality.
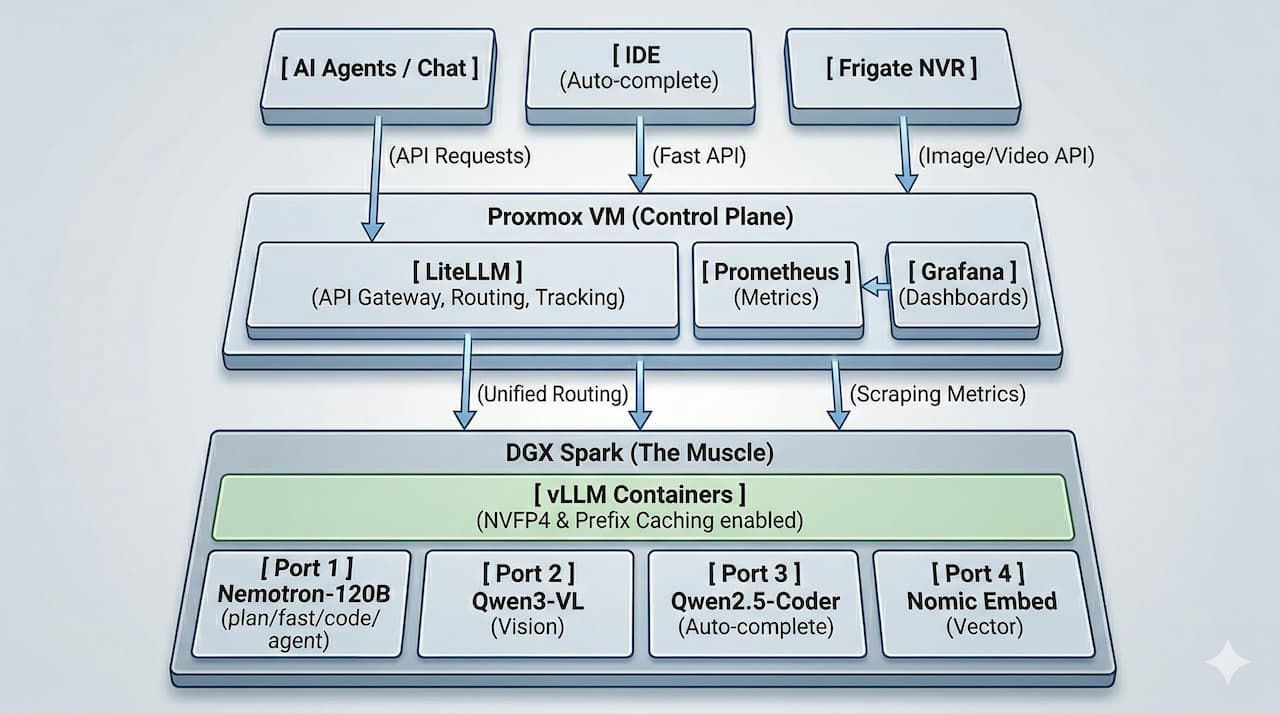
Phase 1: Separation of Concerns (Control Tower vs. The Muscle)
Last time, I ran everything directly on the DGX Spark. But if you want to scale and manage multiple models efficiently, putting all the management overhead on your precious GPU node is a bad idea.
So, I decoupled the architecture. I moved the Gateway & Observability stack onto a separate Proxmox VM:
-
LiteLLM: Acts as the universal API Gateway and Router. It handles every single incoming request (whether it’s text, code, or images), tracks usage, and monitors errors without touching the DGX’s resources.
-
Prometheus & Grafana: Scrapes metrics from both the Spark hardware and vLLM, visualizing GPU loads and performance on a beautiful dashboard.
By isolating the control plane, the DGX Spark becomes purely “The Muscle.” It now strictly runs vLLM, with each model isolated in its own Docker container mapped to a specific port. High availability? Check. No cross-container OOM crashes? Check.
Phase 2: The Return of NVFP4 and a 200k Context Window!
If you read Phase 2 of my last post, you might remember my initial failure trying to run the NVFP4 (Hardware Quantization) format due to Triton/CUDA errors. I had to fall back to FP8.
Well, I am happy to report that NVFP4 is finally working flawlessly! Thanks to Blackwell’s hardware-level quantization, I am now able to cram massive models like Nemotron-120B and Qwen3-VL onto a single DGX Spark simultaneously. The best part? I can leave the Context Size wide open at 200k! Compressing a 120-billion parameter model to run locally with this much context is an absolute game-changer.
Phase 3: Logical Model Routing (1 Model, 4 Personas)
Even with NVFP4, spinning up multiple containers of a 120B model for different tasks would instantly melt the VRAM. My solution? Logical Model Routing via LiteLLM.
Instead of loading Nemotron multiple times, LiteLLM routes different endpoints to the same Nemotron-120B vLLM instance, but injects different parameters (like Temperature and System Prompts). I split it into 4 distinct personas:
-
nemotron-plan(Thinking): Medium temperature. Used for step-by-step logical reasoning and planning. -
nemotron-fast(Thinking, low effort): Low temperature. Still utilizes reasoning capabilities but optimized for speed. Perfect for quick summaries and fast, deterministic answers. -
nemotron-code(Thinking): Tuned specifically for heavy programming logic. -
nemotron-agent(No thinking): Zero temperature. Strict Function Calling to guarantee perfect JSON structure outputs for agentic workflows.
Phase 4: Expanding the Ecosystem (Vision, Auto-complete & Embeddings)
Nemotron is great, but a complete ecosystem needs specialists. I spun up additional isolated containers to handle specific tasks:
-
Qwen3-VL: My dedicated Vision-Language Model. I hooked this up with Frigate to handle smart camera analysis for my NVR setup. Routing Frigate through LiteLLM is fantastic because I can track exactly how many vision tokens the NVR is consuming! It is also an absolute lifesaver during dev/test workflows for analyzing UI screenshots and visual bugs.
-
Qwen2.5-Coder: Dedicated exclusively to Auto-complete. Code completion (like Copilot) requires millisecond latency. Waiting in queue behind a massive 120B model ruins the typing experience, so passing this to a smaller, lightning-fast model is mandatory.
-
Nomic Embed (
nomic-embed-text): The foundation for the future. This model is dedicated entirely to generating Vector Embeddings. It’s sitting there ready to process documents so we can build a 100% local Vector DB for RAG (Retrieval-Augmented Generation).
Phase 5: The Golden Rule — --enable-prefix-caching
The hard-earned lesson from my Claude Code vs. OpenCode battle remains the core pillar of this setup: Prefix Caching is everything.
Every single vLLM container in this new stack runs with the --enable-prefix-caching flag turned on. This is especially critical for nemotron-agent. When you are repeatedly sending massive system prompts (rules, tools, JSON schemas) in agentic loops, caching drops the Time to First Token (TTFT) to near zero and saves massive amounts of KV Cache VRAM.
(And yes, seeing the Cache Hit Rate spike on my new Grafana dashboard is incredibly satisfying!)
Conclusion
This upgrade turned a powerful homelab into a robust, production-ready AI infrastructure. We have the stability of isolated management on Proxmox, the bleeding-edge performance of NVFP4 on the DGX, and the ultimate flexibility of LiteLLM routing.
